

8. 常见ES结构化搜索
mapping说明mapping结构如下
123456789"某字段" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }
term查询注意事项在Elasticsearch中,term查询用于对精确值进行匹配。对于字段类型的考虑,有两个关键点需要注意:
Text vs Keyword: 在Elasticsearch中,text类型的字段通常用于全文搜索,这些字段在索引时会被分词。而keyword类型的字段用于精确值匹配,不会被分词。
使 ...
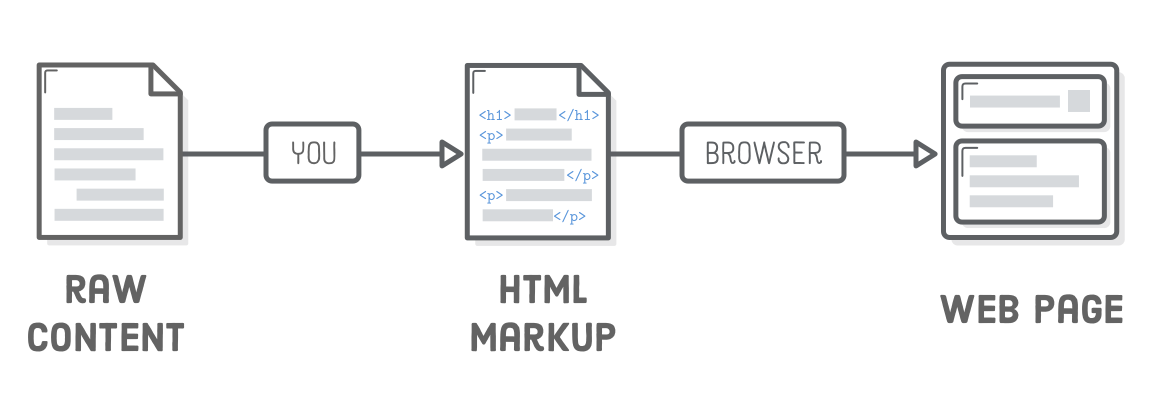
生动的网页知识基础入门
HTML定义了互联网上每个网页的内容。通过使用HTML标签“标记”你的原始内容,你可以告诉网页浏览器你希望如何显示内容的不同部分。创建一个带有正确标记内容的HTML文档是开发网页的第一步。
在这偏文章中,我们将构建我们的第一个网页。由于它不会附加任何CSS,所以看起来会很糟糕,但它将作为对网页开发者日常使用的HTML元素的全面介绍。
当你逐步学习示例时,试着将它们视为类似Google Docs或Microsoft Word的所见即所得编辑器的更实际版本。我们将处理所有相同类型的内容(标题、段落、列表等),我们只是会用HTML更明确地定义它们。
从建立文件开始让我们开始创建一个叫做basic-web-pages的新文件夹。然后,在那个文件夹中创建一个名为basics.html的新文件。这个HTML文件代表一个单独的网页,我们将在这里放置我们所有的代码。
现在你可以双击这个html文件使用浏览器打开它。
记住,网页开发者的基本工作流程是在文本编辑器中编辑HTML并在网页浏览器中查看这些更改,这是你在后面每个部分应该做的事情。
HTML文件的结构向我们的basics.html文件添加以下 ...

svc与ep的关系与使用场景
Kubernetes Service (SVC) 和 Endpoints (EP) 概述Service (SVC)定义Service 是 Kubernetes 中用于暴露应用的一个抽象方式,定义了如何访问一组特定的 Pod。
主要类型
ClusterIP:仅在集群内部可访问的内部 IP。
NodePort:在集群的所有节点上打开一个端口,允许从集群外部访问。同时仍然有内部IP与端口。
LoadBalancer:集成外部负载均衡器。
作用
提供 Pod 的稳定 IP 地址和端口号。
支持多种访问方式,如仅限集群内或集群外访问。
实现 Pod 的服务发现和负载均衡。
Endpoints (EP)定义Endpoints 是 Kubernetes 中的一个资源对象,定义了访问 Service 的一组网络地址。
功能
包含一组 Pod 的 IP 地址和端口号,这些 Pod 被 Service 选择,注意是一组。
是实现负载均衡和服务发现的关键。
关系和相互作用
一对一关系:每个 Service 通常对应一个 Endpoints 对象,通过一样的名称来一一对应。
Service 通过标签选择 ...

抗药性预防
病毒类药物(如抗病毒药)和抗生素(针对细菌的药物)是两种不同的药物,它们的作用机制和使用原则有所不同,但在抗药性的形成和预防方面有一些共通之处。
抗病毒药物:这类药物用于治疗由病毒引起的感染,如流感、HIV/AIDS、某些类型的肝炎等。抗病毒药物的目的是抑制病毒的复制,帮助控制感染。在使用抗病毒药物时,通常也需要完整的疗程,以确保病毒被有效控制,减少抗药性病毒株的出现。
抗生素:这类药物主要用于治疗细菌引起的感染,如肺炎、尿路感染、皮肤感染等。抗生素无效于病毒性疾病。在使用抗生素时,同样重要的是遵循医嘱,完成整个疗程。不完全的疗程或不适当的使用抗生素(例如,用于病毒感染)可能导致细菌抗药性的发展。
抗药性:不论是病毒还是细菌,过度使用或不恰当使用药物都可能导致抗药性的发展。这意味着病原体逐渐适应了药物的作用,使得这些药物日后对其不再有效。因此,无论是抗病毒药物还是抗生素,按照医生的指示完成整个疗程,只在必要时使用,对于减少抗药性的发展非常重要。
奥司他韦(Oseltamivir)是一种广泛用于治疗流感的抗病毒药物。关于吃够5天能减少未来抗药性的问题,这涉及到抗生素和抗 ...

Shell中的文件管理
ls find和 du 是 Linux 和 Unix 系统中非常常用的命令,用于列出文件信息和查看磁盘使用情况。下面是命令的一些常见用法,包括排序、筛选、查看大小、创建时间和修改时间等。
ls 命令的常见用法
基本列表:
ls: 列出当前目录中的文件和目录。
ls -a: 列出所有文件,包括隐藏文件(以.开始的文件)。
长格式显示:
ls -l: 以长格式显示文件详细信息,包括权限、所有者、大小和最后修改时间。
根据修改时间排序:
ls -lt: 按最后修改时间降序排列(最新的文件先显示)。
ls -ltr: 按最后修改时间升序排列(最旧的文件先显示)。
显示文件大小:
ls -lh: 显示文件大小,以易读的格式(例如 KB、MB)。
递归列表:
ls -R: 递归地列出所有子目录的内容。
根据文件大小排序:
ls -lS: 按文件大小排序。
显示文件的创建时间(在支持的系统上):
ls --time=creation -l: 显示文件的创建时间。
du 命令的常见用法
查看目录大小:
du: 显示当前目录的磁盘使用情况。
du -h: 以 ...

MySQL的字符编码
一、MySQL字符编码概述MySQL的字符编码是指数据库中存储文本数据时所使用的字符集。不同的字符集支持不同的语言和符号。字符集(Character Set)和校对规则(Collation)是MySQL中处理字符数据的两个核心概念。
1. 字符集(Character Set)
定义: 字符集决定了哪些字符可以存储以及它们如何存储。它是一种编码方式,指定了不同字符对应的字节表示。
功能: 确定数据库如何理解和存储输入的字符。
2. 校对规则(Collation)
定义: 校对规则是在给定字符集的基础上,定义字符如何进行比较和排序。
功能: 确定在查询和排序时字符如何进行比较。例如,是否区分大小写,如何处理特殊字符等。
总结来说,字符集定义了字符的存储方式,而校对规则定义了字符的比较和排序逻辑。
二、常用MySQL字符编码1. Latin1
编码类型: 单字节
适用场景: 西欧语言
特点: 速度快,节省空间
2. UTF8
编码类型: 变长(最多3字节)
适用场景: 支持多种语言,包括英文、欧洲语言和部分亚洲语言
特点: 兼容性好,灵活
3. UTF8MB4
编码类型: 变长(最 ...

羽毛球步法
前后脚双打时,我方发球和对方发球,都是右脚在前。接发球时是左脚在前。
后场后场击球后,确认步的右脚要往前迈,顺势左脚往后撤,稳住重心,左脚顺势一登,完成回动。
羽毛球握拍
反手握拍训练将平时的握拍改为反手握法,强迫自己来回正反手切换进行训练。

创建GitHub新的SSH密钥
创建GitHub新的SSH密钥
生成新的 SSH 密钥:打开终端(在 Linux 或 macOS 上)或 Git Bash(在 Windows 上),然后运行以下命令来生成一个新的 SSH 密钥:
1ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
将 "your_email@example.com" 替换为你的电子邮件地址。当系统提示你“Enter a file in which to save the key”,输入一个新的文件名,例如 id_rsa_github2。
确保 ssh-agent 正在运行:运行以下命令来启动 ssh-agent:
1eval "$(ssh-agent -s)"
如果你使用的是 Windows,确保你的 SSH 客户端配置正确。如果你使用的是 Git Bash,这些命令应该适用。
将新的 SSH 密钥添加到 ssh-agent:使用你在生成密钥时指定的文件名:
1ssh-add ~/.ssh/id_rsa_github2
将新的 ...

RN音频播放选型
RN音频播放选型react-native-sound 和 react-native-track-player 都是用于 React Native 应用中的音频播放库,但它们的设计重点、功能集和使用场景有所不同。
react-native-sound特点:
react-native-sound 主要用于播放简短的音频文件,例如音效或短信提示音。
它支持基本的音频播放功能,如播放、暂停、停止、重复播放等。
功能:
支持本地和远程音频文件的播放。
允许同时播放多个声音,对于需要同时播放多个短音效的应用非常有用。
提供了基本的音量控制和音频加载状态查询。
使用场景:
适用于播放短音效的场景,如游戏音效、通知声音或用户界面交互音效。
react-native-track-player特点:
react-native-track-player 设计用于长时间的音频播放,特别适合音乐或播客应用。
它提供了更复杂的音频播放控制功能,如播放列表管理、后台播放、事件监听等。
功能:
支持后台播放和控制,允许音频在应用不在前台时继续播放。
提供播放队列管理,可以轻松创建和修改播放列表。
支 ...
