

羽毛球反手发球技巧
羽毛球反手发球技巧之前一直习惯于正手发球,随着打球时间和参加双打活动数量的增长,从今年开始逐步转为反手发球。一开始觉得凭感觉找球感就ok,但随着对手级别的增长,单纯”凭感觉“的反手发球质量达标率已经不能满足实际需求了。
高度初期可以高度低一些,虽然慢,但更容易贴网
站位中线与发球线夹角
脚下右脚在前,脚尖朝前,左脚在后,脚尖朝外
握拍反手握拍:大拇指顶住宽面
持球左手持球,大拇指和食指捏住上方羽毛,球头笔直朝向自己
击球点拍面中心靠右
挥拍手腕不动,小臂撤回到腰部,全程拍面90度垂直地面,向前挥拍,注意左手不要动,发射出去
发力击球后需要持续有一个送出去的感觉,送的方向朝向网袋
进阶击球后,拍面微微向上翻10度左右,会有一个搓球头的感觉,能够让球更快下落,不会又高又慢
方向通过控制击球前通过左手控制球毛的朝向,右手一样的挥拍姿势,可以调整球飞的方向
视频参考来源
李宇轩
鲍春来
陈金
其他,如刘辉,源氏等

CSS的特异性
CSS Specificity(CSS 特异性)是一个用来决定当多个CSS规则应用于同一个元素时,哪个规则将优先应用的机制。在CSS中,特异性是一个权重系统,它根据选择器的类型和数量计算权重。了解和正确应用CSS特异性对于有效地编写和管理CSS样式表至关重要。
特异性的计算规则特异性的计算可以用一个“0-0-0-0”这样的四位数来表示,每一位代表不同类型的选择器:
内联样式(如 style="..."): 每个内联样式计数为 1-0-0-0。
ID选择器(如 #example): 每个ID选择器计数为 0-1-0-0。
类选择器、伪类选择器和属性选择器(如 .example、:hover、[type="text"]): 每个计数为 0-0-1-0。
元素选择器和伪元素选择器(如 div、::after): 每个计数为 0-0-0-1。
计算示例
对于选择器 #navbar .menu a:hover,其特异性为 0-1-1-2。这是因为有1个ID选择器(#navbar)、1个类选择器(.menu)和2个元素选择器(a和:hover)。
选择器 ...

儿童如何科学学习打字?
儿童如何科学学习打字?在这个数字化的时代,打字能力变得日益重要。对于孩子们来说,早期掌握正确的打字技巧,不仅有助于他们的学习,还能培养他们的协调性和反应速度。那么,如何科学地指导儿童学习打字呢?
1. 选择合适的学习工具打字学习工具的选择十分重要。洲洋打字堂 是一个专门的打字学习平台,它特别适合中国的小朋友,因为其汉化做得非常位,确保了孩子们在学习的过程中不会因为语言障碍而受到阻碍。
注: 洲洋打字堂是一个非盈的网站,无需注册和缴费订阅。
2. 重视基本手法正确的手指摆放和基本手法是打字的基础。洲洋打字堂提供了详细的手法指导,教导孩子如何正确地摆放手指,以及个手指应如何移动以敲击不同的键位。开始时速度并不是关键,正确的手法才是最重的。
3. 持续练习学习打字就像学习骑自行车或者游泳,需要时间和练习。洲洋打字堂提供了一系列的练习教程,从最基础的键位始,循序渐进,帮助孩子们逐步建立起打字的信心和技巧。
4. 监督与指导家长和老师在孩子学习打字的过程中起到了至关重要的作用。可以利用洲洋打字的进度跟踪功能,查看孩子的学习情况并根据情况给予必要的指导和鼓励。
5. 培养兴趣和习惯孩子 ...

《构建之法》读书笔记
1 概论软件工程是把系统的、有序的、可量化的方法应用到软件的开发、运营和维护上的过程
程序=数据结构+算法; 软件=程序+软件工程; 软件企业=软件+商业模式
关键词
概念
名称
软件架构
Software Architecture
软件设计与实现
Software Design, Implementation and Debug
源代码管理
Source Code Control
配置管理
Software Configuration Management
质量保障
Quality Assurance
需求分析
Requirement Analysis
程序理解
Program Comprehension
软件维护
Sofware Maintenance
服务运营
Service Operation
软件生命周期
Sofware Life Cycle, SLC
软件项目管理
Project Management
用户体验
User Experience
国际化和本地化
Globalization ...

7. 关于ES数据读写那点事儿
【ElasticSearch系列连载】7. 关于ES数据读写那点事儿1 对文档建索引1.1 自定义文档ID如果数据本身有自己的唯一标记,那么在建立索引时可以使用id来指定文档的id。
如下,使用curl在your_index索引下写入一个id=1001的文档。
12345curl -H "Content-Type: application/json" -XPOST 'http://es00:9200/your_index/_doc/1001' -d '{ "field": "内容"}'
返回如下
1234567{ "_index": "your_index", "_type": "_doc", "_id": "1001", "_version": 1, "resu ...
通俗易懂的分布式原理
通俗易懂的分布式原理简介对于没有实际使用、调试、开发过分布式系统的人来说,横向扩展、数据分区、副本/数据分片、容错容灾, 一致性 等和分布式相关的概念、词汇可能会感觉遥远与深奥。
但是大道至简,殊途同归,相对与不断升级迭代的前端技术升级,目前市面上绝大部分的分布式系统的底层设计思想和理念在近十几年来并没有大的变化,如果我们只关注概念本身,而不是晦涩的技术细节(不同分布式系统的通信协议,实现方案,选举策略,一致性算法,数据分布策略等等),你会发现分布式其实是一个很简单,也很优雅、巧妙的设计理念,是任何技术研发都可以也都应该理解的一个技术概念。
文本结合具体案例尝试进行一个通俗易懂的分布式案例解析。
关于系统的可扩展性当系统的计算资源或者存储资源不足的时候,就需要对系统进行优化或者升级,此时系统的可扩展性(scalability)就显得十分重要了。
虽然你可以通过购买更强大的服务器,来提升你的系统能力,但是这个会受限于单服务器的硬件能力。所以真正的横向扩展需要能够通过添加更多的节点/服务器来提升整个系统的能力:通过添加更多的节点,能够将数据存储和计算任务均衡的分布到各个 ...
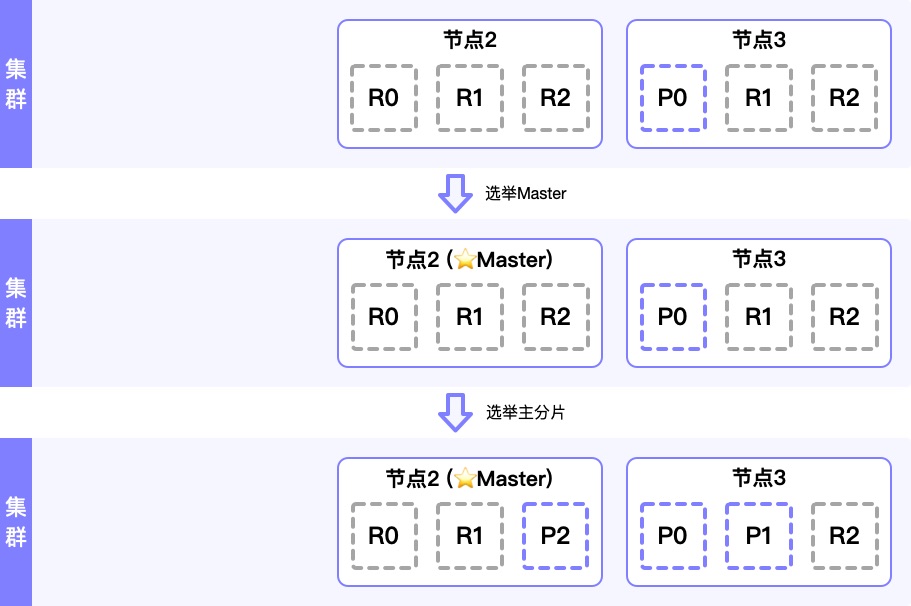
6. ES的分布式原理
【ElasticSearch系列连载】6. ES的分布式原理简介对于没有实际使用、调试、开发过分布式系统的人来说,横向扩展、数据分区、副本/数据分片、容错容灾, 一致性 等和分布式相关的概念、词汇可能会感觉遥远与深奥。
但是大道至简,殊途同归,相对与不断升级迭代的前端技术升级,目前市面上绝大部分的分布式系统的底层设计思想和理念在近十几年来并没有大的变化,如果我们只关注概念本身,而不是晦涩的技术细节(不同分布式系统的通信协议,实现方案,选举策略,一致性算法,数据分布策略等等),你会发现分布式其实是一个很简单,也很优雅、巧妙的设计理念,是任何技术研发都可以也都应该理解的一个技术概念。
文本结合具体案例尝试进行一个通俗易懂的分布式案例解析。
关于系统的可扩展性当系统的计算资源或者存储资源不足的时候,就需要对系统进行优化或者升级,此时系统的可扩展性(scalability)就显得十分重要了。
虽然你可以通过购买更强大的服务器,来提升你的系统能力,但是这个会受限于单服务器的硬件能力。所以真正的横向扩展需要能够通过添加更多的节点/服务器来提升整个系统的能力:通过添加更多的节点 ...

聊一聊前端程序员的现状与挑战
聊一聊前端程序员的现状与挑战前端这一块,得益于日益更新的前端框架降低了入门门槛,得益于目前全自动、半自动化的开发、测试、上线流程,也得益于目前越来越标准的产品设计流程和规范,等等这些都会让你的开发效率和工作量评估更加透明化。
可能让某些类别的前端工作逐步从一个脑力工作者变为劳动密集型的体力工作者。
前端是一个很广很大的领域,有一定的广度和深度;但是不可否认,也许80%的工作都是简单与单调的,随着技术的升级、技术门槛的降低,经过一些简单快速的培训,越来越多的人可以从事这80%的工作 => 整体看,前端的从业人员越来越多,好像越来越卷了。
但是剩余20%的具有一定复杂性、创造性、创新性、架构设计性、挑战性的工作,却不会受到太多影响,大部分情况,也正是这大约20%的工作,决定了一个产品、一个公司、一个团队的关键部分,所以如何具有足够的能力、经验和理论来承担、组织更具有价值和挑战性的这20%的工作,伴随解决挑战性问题的实战积累更多的经验和解决问题的能力,进入一个正向循环是在开发过程中不断成长和晋升的关键。
所以,前端的入门门槛低了,原本对你来说已经掌握技术的和不容易实现的内容, ...
5. ES入门基础与常见操作
【ElasticSearch系列连载】5. ES入门基础与常见操作1 ES 数据格式-JSON我们要存储的对象通常不是简单的键值对就能表示的,更多的情况是需要存储更加复杂的数据结构,比如数组、地址、嵌套结构等等。
如果我们使用传统的关系型数据库进行常见的行列存储的话,很多情况我们都需要将一些复杂的数据结构拍平,通过构造一个宽表来存储你的数据,或者需要将你的数据通过逗号分隔等形式拥挤的存储在一个字段中,每次从数据库写入和读取数据都需要进行序列化和反序列化的操作。
Elasticsearch是面向文档的,能够直接将复杂的对象进行存储,同时还能对复杂数据结构中的各个字段建立索引来让它能够被高效的检索到。在使用Elasticsearch的过程中,你建立索引的对象、搜索的对象、排序的对象以及筛选的对象都是文档,而不是行列格式的关系型数据,这是ES和其他关系型数据库最大的不同之一,以及为什么ES能够提供复杂的全文搜索。
ElasticSearch使用JSON (JavaScript Object Notation) 作为文档的存储结构。目前绝大多数语言都能友好地支持JSON格式数据的转化与传输 ...

3. 如何安装符合生产环境要求的ES集群
【ElasticSearch系列连载】3. 如何安装符合生产环境要求的ES集群通过本文,将会循序渐进地了解到ES的若干部署方案,以及相关的基础操作与配置。
上一节介绍的一键安装方式,可以快速启动一个ES环境用于学习,调试和测试,但是还不足以作为生产环境,比如:
不支持集群模式
无法轻易对配置文件进行调整与维护
后续写入的搜索数据会随着容器删除而删除,没有在本地进行持久化存储
9200端口暴露,不需要认证即可访问存在安全隐患
没有可视化管理界面(kibana)
本文将会依次解决持久化存储(包括数据文件与配置文件)、可视化管理(kibana)和加密(ES+Kibana)的问题,各个章节解决的问题如下:
章节
单节点
集群
数据持久化
kibana
加密
3.1
✅
3.2
✅
✅
3.3
✅
✅
✅
3.4
✅
✅
✅
✅
4.1
✅
✅
4.2
✅
✅
✅
4.3
✅
✅
✅
✅
1 版本与环境选型1.1 ES版本选择考量本系列使用ES 7.10版本作为部署选型
截止到目前撰稿日期,已经推出了ES 8.0版本, ...
