通俗易懂的分布式原理
通俗易懂的分布式原理
赵洲洋通俗易懂的分布式原理
简介
对于没有实际使用、调试、开发过分布式系统的人来说,横向扩展、数据分区、副本/数据分片、容错容灾, 一致性 等和分布式相关的概念、词汇可能会感觉遥远与深奥。
但是大道至简,殊途同归,相对与不断升级迭代的前端技术升级,目前市面上绝大部分的分布式系统的底层设计思想和理念在近十几年来并没有大的变化,如果我们只关注概念本身,而不是晦涩的技术细节(不同分布式系统的通信协议,实现方案,选举策略,一致性算法,数据分布策略等等),你会发现分布式其实是一个很简单,也很优雅、巧妙的设计理念,是任何技术研发都可以也都应该理解的一个技术概念。
文本结合具体案例尝试进行一个通俗易懂的分布式案例解析。
关于系统的可扩展性
当系统的计算资源或者存储资源不足的时候,就需要对系统进行优化或者升级,此时系统的可扩展性(scalability)就显得十分重要了。
虽然你可以通过购买更强大的服务器,来提升你的系统能力,但是这个会受限于单服务器的硬件能力。所以真正的横向扩展需要能够通过添加更多的节点/服务器来提升整个系统的能力:通过添加更多的节点,能够将数据存储和计算任务均衡的分布到各个节点上,并保障服务的性能的稳定性。
从一个空集群开始-master node
在一开始,我们先启动一个新的节点,没有数据和表/索引,此时的状态如下图。

由于目前集群只有一个节点,所以这个节点很自然地被选举为”Master节点”。
“Master节点”,顾名思义就是主节点,是负责集群层面主要操作的节点,如:表/索引的创建和删除,节点的添加和删除。另外的操作,比如文档数据的增删改查都不需要它,任何的节点都可以,所以在和数据相关的操作上,只有一个”Master节点”不会成为吞吐量的瓶颈。
作为集群的使用者或者调用方,我们一般可以和集群的任何一个节点(包括Master)直接进行通信,因为任何一个节点上都记录了所有数据的实际存储位置(只记录地址信息),并将请求正确的转发到多个对应的节点上,并将返回进行合并后统一返回给调用方。所以任何一个节点都可以承担核心数据的增删改查操作。
数据分片-主要(Primary)分片和副本(Replica)分片
在集群的实际存储中,一个表/索引是由一个到多个物理分片(Shard)组成的。
每个分片(Shard)负责存储表/索引的一部分数据,而一个节点可以存储多个分片。当集群节点扩充或者削减的时候,集群会自动的将数据分片(Shard)在节点之间进行拷贝、移动,确保所有节点承担的数据和计算任务是相对均衡的。
我们在实际的使用过程中,通常并不用关注分片(Shard),而是直接使用集群的接口或者SDK与表/索引通信即可。
一个分片(Shard)要么是”主要”(Primary)分片,要么是”副本”(Replica)分片,你的任意一条数据一定会在出现一个主要(Primary)分片中,所以集群里主要(Primary)分片中包含的数据总量,就是集群实际存储的数据总量。
而副本(Replica)分片,顾名思义,就是主要(Primary)分片的拷贝,用于:
- 对数据进行冗余存储,来规避如硬件损坏带来数据丢失的问题
- 也可以提供数据的”只读”类型服务,比如获取数据或者查询数据,提高整个系统的并发性能
所以,在数据量不变的情况下,主要(Primary)分片的数量是固定的,而副本(Replica)分片的数量则是可以随时调整的。
现在,我们建立一个数据表,设置为:
- 使用3个分片来存储这个数据表
- 创建1份冗余副本
此时,集群状态如下图。

可以看到,有三个主要(Primary)分片P0, P1, P2存储在了节点1中。但是并没有看到冗余副本的存储。
因为如果副本(Replica)分片和自己的主要(Primary)分片存储在一台机器上是没有意义的,既不能容灾,也不能提供额外的读取性能。所以目前只有一个节点的情况,不管设置了多少分冗余副本的配置,都不会实际创建副本。
集群容灾-新增一个节点
只启动一个节点无法对集群进行容灾:如果这个节点故障了,所有的服务和数据也就随之发生了故障。现在,我们启动第二个新的节点”节点2”加入集群中。

如图,随着”节点2”的加入,刚才由于节点数量不足而没有创建的副本(Replica)分片R0, R1, R2已经被自动创建并写入”节点2”。这样,不管是”节点1”还是”节点2”宕机,我们的数据都不会丢失了。
一条数据新建时,会优先拷贝到数据所属数据表的主要(Primary)分片,然后再并行的拷贝到这个分片对应所有的副本(Replica)分片中,来保障数据的一致性。
横向扩展-再加一个节点
此时,我们再新增一个”节点3”,集群中的数据会变成如下的存储状态。

可以看到,原来”节点1”的P0分片和”节点2”的R2分片移动到了新的”节点3”上,从每个节点有3个分片变成了每个节点有2个分片,意味着每个分片可以占有的CPU/内存资源更多了。
通过这样负载均衡策略,可以通过增加节点,来让每个节点的性能进行提升,从而提升整个集群的性能。
在集群中,每个分片都可以充分利用所在节点的CPU/内存/存储资源。目前,我们一共有六个数据分片(P0-P2, R0-R2),所以目前这个集群最多可以六个节点(每个分片独占一个节点)。
让数据拥有更多副本
如上文所述,假如一共就6个分片,如果我们的集群节点数量大于6个的话,需要如何调配来尽可能发挥所有节点的能力?
如上文所述,副本分片虽然不会承担数据写入的任务,但是可以提供数据”只读”类型服务,比如获取数据或者查询数据。所以虽然”主要分片”的数量是固定的,但是我们可以通过增加”副本”的数量,来提高整个系统的并发性能,尤其是对于频繁读取和搜索的系统,整体性能的强弱很大程度取决于副本的数量。
比如,我们将刚才的数据副本数从1调整为2,可以看到目前的集群状态如下图:一共有3个主要分片和6个副本分片。并且现在如果任意两个节点宕机,都不会造成数据的丢失。

这种情况下如果我们把节点数量扩展到9个,就可以让每个节点存储一个分片,对应的数据读取/查询性能会变为现在的3倍。
容灾模拟-删除一个节点
现在,我们把”节点1(Master节点)”进行关机操作。
首先,集群时刻都需要一个”Master节点”来保障整体集群的正常运转,所以集群自动进行的第一个操作,就是选举出一个新的”Master节点”: “节点2”。
然后,由于P1和P2在已经关机的”节点1”上,在没有”主要分片”的情况下,也是无法支撑正常数据服务的。但好在我们”节点1”上所有的主要分片P1和P2在其他节点上都有副本,所以接下来,需要从”副本分片”选举出新的”主要分片”:”节点2”的R2升为P2,”节点3”的R1升为P1。
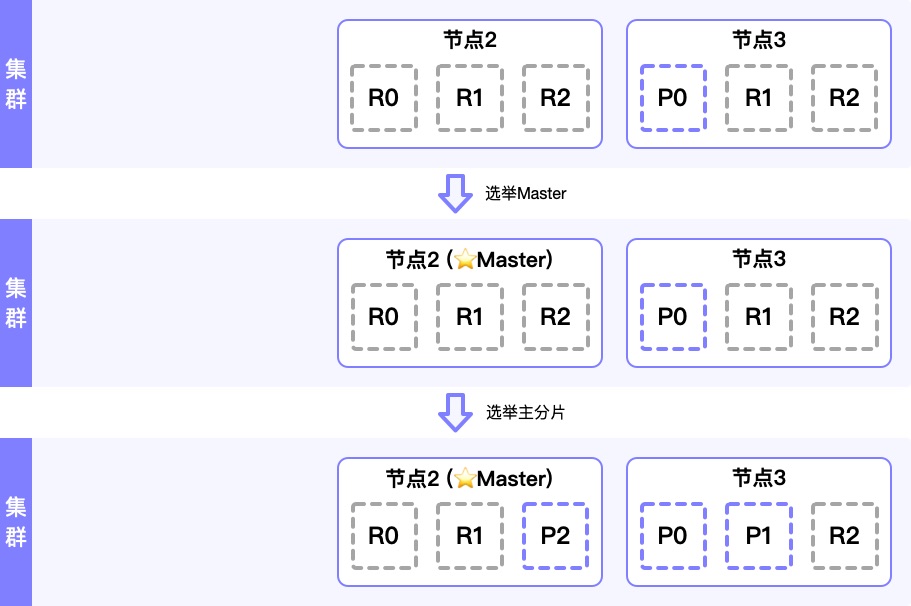
此时,虽然已经关闭了”节点1”,剩余的”节点2”和”节点3”仍然具有”容灾”的能力,因为每一个节点上都有所有的分片1~3数据(主要的或者副本的)。
总结
通过这些样例,应该能够对数据分片有了更好的理解:
- 通过数据分片如何让集群进行横向扩展
- 通过数据分片如何让集群具有容灾能力
在后续的内容中,会对分布式进行更加深入的分析。